Para entender o que é HTML, ou qualquer tecnologia, acredito que é muito importante conhecer um pouco da sua história, pois a partir dela é possível entender o que motivou sua criação, o porquê de suas características e para que ela é utilizada hoje em dia. Com isso, neste artigo, vamos abordar o conceito de HTML, bem como outros pilares importantes para seu entendimento, como: o que é a World Wide Web, o que é o protocolo HTTP e um pouco de como funcionam as redes de computadores.
Começando pela definição, HTML é a sigla para HyperText Markup Language, ou Linguagem de Marcação de Hipertexto. Ao destrinchar esse termo, notamos a palavra hipertexto, um conceito fundamental que, diferentemente do que muitos podem pensar, surgiu bem antes do próprio HTML e até mesmo da WWW. A história do hipertexto é bastante longa e o que vou trazer é apenas uma visão geral das partes mais importantes.
Uma breve história do Hipertexto
Hipertexto (ou Hypertext), em termos gerais, é um documento que contém links para outros documentos. Sua história começa em 1945, quando Vannevar Bush publicou uma proposta de sistema que seria o primórdio para o que conhecemos hoje como um sistema de hipertexto. Esse sistema, o Memex (“extensor de memória”), nunca foi implementado, mas foi descrito em teoria nos artigos de Bush. De forma simplificada, Bush descreveu o Memex como “um dispositivo no qual um indivíduo armazenaria seus livros, registros e outros tipos de texto, mecanizado de uma forma que possa ser consultado com extrema velocidade e flexibilidade”, resultando em uma espécie de “arquivo de biblioteca privado e mecanizado”.
A palavra hipertexto foi utilizada pela primeira vez apenas em 1965, por Ted Nelson, no desenvolvimento do seu sistema Xanadu. A ideia básica do Xanadu era a de um repositório para tudo que alguém já escreveu e, portanto, um verdadeiro hipertexto universal. O Xanadu, no entanto, nunca foi implementado, mas trouxe a visão de Nelson do hipertexto como um meio literário, e a crença de que “tudo está profundamente interligado” e, portanto, precisa estar online.
Nos anos seguintes, diversos outros sistemas de criação e edição de hipertexto foram criados, como os NoteCards da Xerox e o Intermedia da Brown University (anunciados por volta de 1985). Outros foram o Guide, lançado em 1986 como o primeiro hipertexto amplamente disponível para computadores pessoais comuns, e o HyperCard (1987), que foi um produto que realmente representou um passo final para o “mundo real”, sendo provavelmente o produto de hipertexto mais famoso do final da década de 1980. Além da criação desses sistemas, conferências e periódicos ocorridos no final da década de 1980 aumentaram a popularidade do hipertexto na criação de sistemas que vinculavam arquivos através de links, pois estes permitiam uma forma muito mais fácil de navegar pelas informações presentes em arquivos da própria máquina do usuário ou de um grupo restrito de computadores.
Origem da World Wide Web
Com o crescimento do hipertexto, a evolução das tecnologias de computadores e das redes de dados, Tim Berners-Lee, enquanto trabalhava no CERN, um centro de pesquisa localizado na Suiça propôs a criação da World Wide Web (WWW) em 1989, que buscava fundir essas tecnologias em um sistema de informação global poderoso e fácil de usar. A Web foi inicialmente desenvolvida para atender à demanda por compartilhamento automatizado de informações entre cientístas em universidades e institutos ao redor do mundo.
Tim Berners-Lee escreveu sua primeira proposta para a World Wide Web em março de 1989, e sua segunda proposta em maio de 1990, documentos que delinearam os principais conceitos e termos importantes por trás da Web. A proposta descreveu um projeto de hipertexto chamado “WorldWideWeb”, no qual uma teia (ou web) de documentos de hipertexto poderia ser visualizada por navegadores. A partir de então, no final de 1990, Tim Berners-Lee apresentou o primeiro servidor web e navegador instalados e funcionando no CERN, demonstrando suas ideias.
Como acessamos a World Wide Web?
De forma simplificada, o acesso à World Wide Web (WWW) é feito pela Internet, através do seu navegador, seguindo uma arquitetura cliente-servidor. Nela, o cliente (o navegador) inicia a comunicação, enviando uma requisição (usando o protocolo HTTP/HTTPS) ao servidor web. Essa requisição HTTP é encapsulada e transportada pelo TCP/IP até o destino. O servidor web, por sua vez, processa a solicitação e retorna o conteúdo da página (como arquivos HTML, CSS e JavaScript) para ser exibido na tela do usuário, também através do navegador.
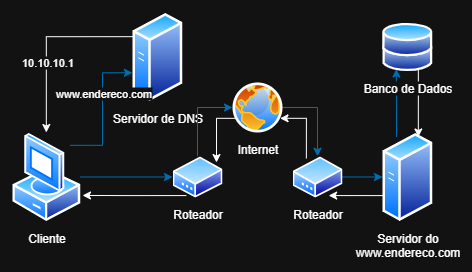
Um protocolo é um sistema de regras que define como o dado trafega dentro ou entre computadores. O protocolo TCP/IP é dividido em diversas camadas, com diferentes protocolos em cada uma. O TCP (ou Transmission Control Protocol) faz parte da camada de transporte, e o IP (ou Internet Protocol) da camada de rede. O protocolo TCP/IP basicamente dita regras para que duas máquinas se comuniquem e define cuidadosamente como as informações se movimentam de remetente para receptor. O protocolo HTTP (ou Hypertext Transfer Protocol), também criado por Tim Berners-Lee, é um protocolo da camada de aplicação do TCP/IP. Como o nome sugere, é um protocolo para transferência de hipertextos, e foi criado em 1990. Outro termo importante ao falar do protocolo HTTP, é o DNS (ou Domain Name System), que é um sistema de endereçamento de domínios. O DNS traduz o endereço web que você digita (o domínio) para o respectivo endereço IP real do servidor, permitindo que o protocolo TCP/IP estabeleça a conexão e permita a troca de dados HTTP.
O protocolo HTTP usado nessas fases iniciais era muito simples e com o tempo recebeu atualizações, ganhando mais flexibilidade. Atualmente, documentos diferentes de arquivos de hipertexto podem ser transmitidos, como imagens e vídeos. Ocorreram melhorias também na segurança, através da criação do HTTPS — uma versão do HTTP com uma camada adicional de transmissão criptografada (o SSL), criada pela Netscape Communications — e que é o mais utilizado até hoje.
Continuando um pouco a história desse protocolo, mas com algo que não vai importar muito para esse artigo: em 2000, um novo padrão para uso do HTTP foi criado, a Transferência de Estado Representacional, mais conhecida como REST. Isso deu origem à arquitetura REST e à criação de APIs web baseadas nessa arquitetura, a famosa API REST.
Finalmente, o HTML
O HTML é o formato textual utilizado para representar os documentos de hipertexto transferidos via HTTP. É a espinha dorsal de toda página da web e é a linguagem utilizada para estruturar o conteúdo que será disponibilizado no navegador. Como o próprio nome sugere, HTML não é uma linguagem de programação, mas sim uma linguagem de marcação. Ela consiste em instruções que, através de tags (elementos entre < e >), dão significado aos dados, indicando ao navegador o que é um título, um parágrafo, uma imagem, e assim por diante.
A abordagem dos protocolos (HTTP/HTTPS e TCP/IP), das redes de computadores e da World Wide Web serviu apenas para contextualizar o HTML. Pretendo detalhá-los mais em artigos futuros e específicos para cada um. A partir de agora, farei um rápido tutorial de HTML, pois acredito que a melhor maneira de aprender é fazendo, e não apenas lendo. Este blog terá sua primeira versão cobrindo o básico do desenvolvimento web front-end, e ficará disponível em um repositório público no GitHub. Conforme escrevo, vou atualizando-o para que sirva como um projeto prático.
O básico do HTML
Um arquivo HTML é composto por tags de marcação para indicar ao navegador a estrutura do seu conteúdo. No HTML5, por exemplo (que é a versão que vou utilizar daqui para frente), ao escrever “html:5” e apertar Enter em um arquivo HTML no VS Code, ele gera a estrutura inicial para um arquivo HTML5. A imagem a seguir mostra um print do resultado que aparece no navegador. Nesse print, temos o resultado do código HTML junto com um print do próprio código HTML que gerou esse resultado (?????).
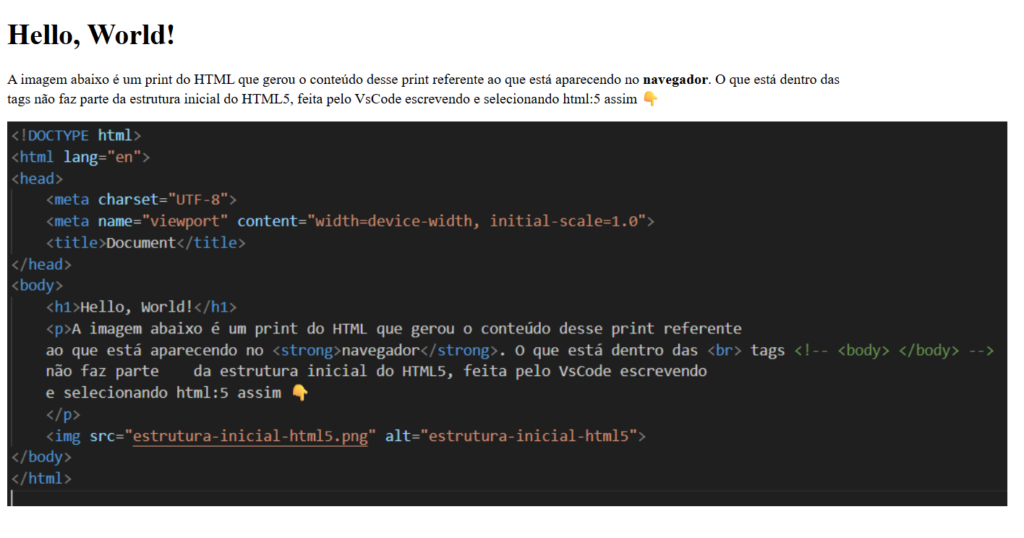
(Eu não sei se deu para entender o que eu fiz, espero que sim. Se não entendeu, tudo bem, eu também não sei se entendi minha própria explicação.)
Vou explicar o básico da estrutura, baseando-me no código da imagem. Um elemento HTML é o bloco fundamental e é delimitado por duas partes: uma tag de abertura e uma tag de fechamento. Por exemplo, as tags <p> e </p> servem para definir um parágrafo. O texto que fica entre elas é o conteúdo desse elemento.
As tags podem ser aninhadas, ou seja, elementos são colocados uns dentro dos outros. Por exemplo, se usarmos as tags <strong> e </strong> para envolver uma palavra, como a palavra “navegador”, ela resultará em um texto em destaque dentro de um parágrafo (<p>).
Outro tipo é o elemento vazio (ou self-closing), que é composto por apenas uma tag e não possui conteúdo interno. A tag <img> é um exemplo clássico, utilizada para inserir uma imagem na página. Ela não precisa de fechamento, pois não envolve texto.
Documentos HTML também aceitam comentários, como pode ser observado na imagem. Os comentários são usados para organizar ou explicar o código para outros desenvolvedores e são ignorados pelo navegador. Em HTML, os comentários são delimitados pela sintaxe <!-- conteúdo do comentário -->.
Além dos elementos que definem blocos de conteúdo, existe a tag <br>. Ela é um exemplo de elemento vazio que é utilizada para inserir uma quebra de linha. Usar <br> força o texto a continuar na linha de baixo, sem iniciar um novo parágrafo.
Continuando com os elementos da estrutura inicial, temos o elemento <body>, que contém todo o conteúdo que será exibido na página. O elemento <head> contém metadados, ou seja, informações sobre o documento que não são necessariamente expostas ao cliente, mas que são cruciais para o navegador. Em resumo, dentro do <body> ficam os elementos visuais, e no <head> ficam os metadados.
O elemento <html> é o elemento que engloba todo o conteúdo do arquivo HTML, sendo considerado o elemento raiz. Outro componente presente na imagem é o <!DOCTYPE html>. Essa instrução não é uma tag, mas sim uma instrução para que o navegador identifique o tipo de documento que está lendo, que no nosso caso, é o modo padrão de renderização do HTML5.
Por fim, dos elementos mostrados na imagem, o último é o <title>, que define o título da sua página. É o nome que aparece na barra de guias do seu navegador, na sua lista de favoritos, e no resultado de busca. Esse elemento não é só estético, mas um elemento muito importante, pois é a principal informação utilizada pelos motores de busca para indexar e encontrar seu site.
Existem muitos outros elementos importantes além dos citados, essenciais até mesmo para construir uma página simples. Estes incluem elementos para diferentes tipos de mídia, tabelas, formulários, listas, estrutura semântica e organização de layout, entre outros. Você facilmente os encontrará com rápidas pesquisas. Não é necessário decorar todos esses elementos, e, sinceramente, não considero que valha a pena esse esforço, é algo que você aprende conforme a prática e a necessidade, ou fazendo qualquer projeto de algum tutorial na internet.
| Tipo de Elemento | Exemplos de Tags | Função Principal |
| Mídia | <audio>, <video>, <embed> | Incorporar conteúdo externo e multimídia (áudio e vídeo). |
| Tabelas | <table>, <tr>, <td>, <th> | Organizar dados em linhas e colunas. |
| Formulários | <form>, <input>, <button>, <textarea> | Coletar dados de entrada do usuário. |
| Listas | <ul>, <ol>, <dl> | Estruturar itens de forma ordenada ou não ordenada. |
| Estrutura Semântica | <header>, <nav>, <main>, <section>, <footer> | Dar significado e hierarquia clara às diferentes partes do conteúdo. |
| Organização de Layout | <div>, <span> | Agrupar elementos para estilização (CSS) ou manipulação (JavaScript). |
Fontes de Consulta e Leitura Recomendada
- A Short History of the Web (CERN)
- A Brief History of Hypertext (The History of the Web)
- Hypertext: History (Nielsen Norman Group)
- Como a Web funciona (Mozilla Developer Network – MDN)
- Evolução do HTTP (Mozilla Developer Network – MDN)
- HTML: Linguagem de Marcação de Hipertexto (Mozilla Developer Network – MDN)
- Protocolos TCP/IP (IBM Docs)